
파이프라이닝 ( Pipelining)
1. CPU 개요 ( CPU Overview)

중앙 처리 장치( CPU)는 컴퓨터 시스템을 통제하고 프로그램의 연산을 실행 또는 처리하는 컴퓨터의 제어장치이다. 중앙 처리 장치( CPU)는 프로그램의 명령어를 해석하고 연산하고, 외부로 출력하는 역할을 한다.
중앙 처리 장치( CPU)의 기본 구성으로는 처리할 명령어를 저장하는 프로세스 레지스터, 비교, 판단, 연산을 담당하는 산술논리연산장치(ALU), 내부버스, CPU를 제어하는 제어부 등이 존재한다.

CPU에서 동작하는 파트를 나누면 왼쪽 사진과 같이 나눠볼 수 있다.
해당 부분들이 한 싸이클 작동하면 한 번의 동작을 한다고 가정했을 때,
CPU가 여러가지 일을 처리할 때 한 사이클씩 작동한다면 , ALU가 작동하는 동안 Data access파트가 놀게 되고, Data access가 작동하는 동안 ALU는 쉬게 된다. 이는 굉장히 비효율적이라 생각할 수 있다.
어떻게 해야 더 효율적인 중앙 처리 장치( CPU)가 될 수 있을까??
2. 파이프라이닝 ( Pipelining)
위의 질문을 해결할 수 있는 방법은 파이프라이닝( Pipelining)이다. 파이프라이닝이란? 같은 CPU회로 안에서 여러 명령들이 단계마다 연속적으로 수행되는 것이다.
가장 유명한 예시로 세탁물 예시가 있다. CPU가 한 사이클에 명령어를 가져오기, 해석하기, 실행하기, 결과 4단계로 이루어져 있는 것을 옷을 세탁하여 옷장에 넣는 것까지 세탁기에 넣기, 건조하기, 옷을 개기, 옷장에 넣기 4단계에 매핑하여 생각하면 쉽다.
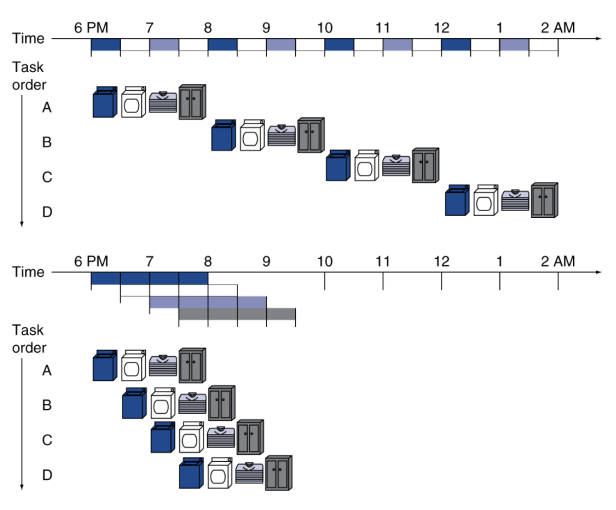
집에서 여러번 세탁해서 옷장에 옷을 집어넣어야 하는 경우 위의 4단계를 그냥 실행한 경우 첫 번째 그림과 같이 시간이 많이 걸리게 된다. 더 효율적으로 하려면 어떻게 해야 할까?
세탁을 한 후 건조기에 옷을 넣으면 세탁기가 놀고 있는다. 그때 세탁기에 옷을 또 넣고, 첫 번째 빨랫감을 건조기에서 빼서 옷을 개는 동안 건조기는 놀고 있는다. 그때 두 번째 빨랫감을 건조기에 넣고, 세 번째 빨랫감을 세탁기에 넣는다.
놀고 있는 파트가 없이 병렬적으로 처리를 하면 된다.
이와 같은 예시의 방식이 파이프라이닝의 핵심로직이다. 즉 파이프라이닝은 동시에 여러 개의 일을 처리함으로써 효율적으로 같은 시간 내의 많은 일을 처리하는 것이다.
이를 CPU에 대입하여 한 사이클에 명령어를 가져오기, 해석하기, 실행하기, 결과 4단계로 이루어져 있다 할 때, 첫 명령이 해석하기 단계로 넘어가면 두 번째 명령을 가져오기를 함과 동시에 진행하며, 첫 명령이 실행하는 단계인 경우 두 번째 명령을 해석하며, 세 번째 명령을 가져오는 것이다. 이처럼 병렬적으로 명령을 처리하게 된다면, CPU를 더 효율적으로 사용할 수 있게 되는 것이다.
3. 파이프라이닝 성능 ( Pipelining Hazards)

첫 번째 단일 사이클의 경우 명령어 사이의 평균 시간은 800ps, 두 번째 파이프라인 명령어 사이의 평균 시간 200ps이 걸린다. 단일 사이클보다 병렬적으로 파이프라인 방식으로 CPU에서 명령어를 처리하는 게 효율적이라는 것을 알 수 있다.
파이프라이닝이 4배 효율적이라면, 많은 명령어를 처리하는 CPU도 무조건 4배 더 효율적일까?
실제로는 그렇지 않다. 여러 가지 변수가 생길 수 있는데 이런 파이프라이닝 성능을 방해하는 것들을 해저드( Hazards)라고 한다.
해저드 ( Hazards)
CPU가 파이프라이닝으로 병렬적으로 처리하게 될 때 "다음 사이클에서 다음 명령어를 시작하지 못하게 하는 상황"을 해저드( Hazards)라 한다. 위의 세탁물 예시를 이어서 해저드를 설명해 보면, 두 번째 명령이 세탁이 끝나서 건조기에 넣을라 했는데, 세 번째 명령을 세탁기에 못 넣는 경우이다. 이런 문제점은 3가지로 분류되는데 구조적 해저드 ( Structure Hazards), 데이터 해저드 ( Data Hazard), 제어 해저드 ( Control Hazard)으로 분류된다.
- 구조적 해저드 ( Structure Hazards)
- 데이터 해저드 ( Data Hazard)
- 제어 해저드 ( Control Hazard)
1. 구조적 해저드 ( Structure Hazards)
구조적 해저드( Structure Hazard)는 리소스 사용에 대한 충돌을 의미한다. 세탁기에 새로운 빨랫감을 넣으려는데 이미 세탁기가 사용 중인 경우이다. 이런 케이스에는 MIPS 파이프라인이 단일 메모리를 1개만 사용하는 경우가 있다.
CPU의 4단계는 가져오기, 해석하기, 실행하기, 결과로 있는데, 결과를 저장하는 것도 메모리를 사용하고, 어떤 명령을 가져오는 첫 번째 단계도 메모리를 사용하는데, 병렬적으로 CPU를 사용하는 과정에서 단일 메모리라면, 결과를 저장하면서 새로운 명령을 가져오는 단계에서 메모리는 둘 중 하나의 단계만 수행할 수 있다. 이와 같은 경우에는 파이프라인에 버블( bubble)이 발생했다고 한다.
예시로 정리하자면, 구조적 해저드( Structure Hazard)는 세탁기 사용하려 했더니 구조적으로 세탁기가 이미 사용 중 이거나 다른 이유로 사용할 수 없는 경우이다.
2. 데이터 해저드 ( Data Hazard)


왼쪽과 같은 어셈블리어가 있다고 할 때 $S0은 add연산에서 시행된 값이며, 두 번째 sub연산에 사용된다. 이것이 왜 문제가 되냐?
첫 번째 연산이 끝이 나지 않은 경우, 파이프라인과 같이 병렬적으로 처리가 될 때 두 번째 연산에서 $S0을 사용할 수가 없다는 뜻이다. 이처럼 "이전 명령어에 의한 데이터 액세스 완료에 따라 현재 명령어가 딜레이 되는 것"을 데이터 해저드( Data Hazard)라 한다.

이를 조금이라도 극복하고자 사용하는 방법은 첫 명령어의 단일 사이클 끝까지 기다린 이후에 레지스터에서 다시 $S0을 가져오는 것이 아닌, 중간에 산술처리만 된 이후에 레지스터에 저장하기 전에 미리 받아오는 것이다. 이 방법을 Forwar ding이라 하며, Bypassing이라고도 불린다. 예를 들어 이번 빨랫감을 다음 빨랫감과 함께 다시 말려야 하는데, 세탁물을 개서 옷장에 넣었다 다시 빼는 것보다 개기 전에 다른 빨랫감이랑 같이 건조기에 넣는다고 이해하면 쉽다.
3. 제어 해저드 ( Control Hazard)
분기 명령어( jump, branch)에 의해 발생하는 해저드를 제어 해저드( Control Hazard)라고 한다. jump 또는 branch 등 분기가 결정된 시점에, 파이프라인에 잘못된 명령이 있는 경우에 발생한다.
예를 들어 세 줄의 명령이 병렬적으로 이미 처리 대기 중이라 할 때, 첫 줄의 명령이 true이어야만 두 번째 줄의 명령이 실행된다고 할 때, 첫 번째 줄이 False임에도 이미 병렬적으로 명령이 처리 대기 중이기 때문에 실행되게 된다.
첫번째 빨랫감들이 모두 빨래과정을 마친 후 엄마한테 허락받고 두 번째 빨래를 시작해야 하는데, 이미 두 번째 빨랫감이 세탁기에 들어가 버린 상황인 것이다.
이를 해결하기 위해 Stall on Branch방식과 Predict Branch방식등이 존재한다.
- Stall on Branch
어떤 분기를 만난다면, 다음 명령어를 가져오기 전에 분기 결과가 결정될 때까지 기다리는 방식이다. 위의 그림을 보면 or명령은 400ps를 더 기다리고 있는 것을 볼 수 있다.

- Predict Branch
파이프라인이 길면 분기 결과를 조기에 쉽게 확인할 수 없다. 즉 Stall on Branch가 허용되지 않는 것이다.
이러한 경우 사용하는 방식이 분기 결과를 예측하는 방법이다. 예측이 잘못된 경우에만 정지를 한다면, Stall on Branch의 단점을 극복할 수 있는 것이다.

'Computer Science' 카테고리의 다른 글
| [데이터 통신] 정보의 압축 ( 무 손실 압축, 손실 압축) (0) | 2024.04.14 |
|---|---|
| [데이터 통신] 정보의 형태와 디지털화 ( 아날로그, 디지털 ) (2) | 2024.03.12 |
| [시스템 소프트웨어] 왜 컴퓨터에서는 10진수가 아닌 2진수를 사용할까? (1) | 2023.10.18 |
| [시스템 소프트웨어] unsigned와 signed의 차이 / signed의 음수 표현 (1) | 2023.10.17 |